

Lorsque vous avez commencé à développer votre premier projet PHP, vous étiez loin de vous douter que les plus gros défis à venir ne seraient pas liés à votre code base. Il faut reconnaître que vos journées sont bien différentes de ce à quoi vous vous attendiez.
Vous gérez des temps d’arrêt une ou deux fois par semaine, vous êtes incollable sur les disques durs, et vous procédez à un débogage en production un jour sur deux (quand je dis débogage, je ne parle pas de xdebug ; je pensais plutôt à var_export et debug_backtrace pour un fichier journal).
Alors que vous preniez tranquillement le thé avec un ami l’autre jour, voilà qu’une nouvelle question a surgi pendant la discussion : comment fonctionne votre pipeline de release ?
Vous commencez alors à expliquer le processus : « Je vais là… puis je crée ça … un login ici… j’exécute une commande… je vérifie qu’il… », puis c’est la révélation : le pipeline de release, c’est vous ! Si vous n’êtes pas dans le bureau, rien ne se passe !
Or, nous sommes en 2019 – on peut faire mieux. Et non, vous n’êtes pas obligé de remanier un million d’éléments pour tirer profit des nouvelles technologies ou pratiques. Mais il faut bien commencer quelque part, et dans ce cas j’imagine que vous n’utilisez pas AWS pour votre projet PHP, et que vous êtes prêt à le faire.
POURQUOI ? AWS vous permet de poser des bases saines, pour un développement plus efficace et un déploiement plus rapide afin d’apporter davantage de valeur à vos clients.
Je vais vous décrire le scénario idéal, et vous pourrez choisir les fonctionnalités et services que vous souhaitez utiliser.
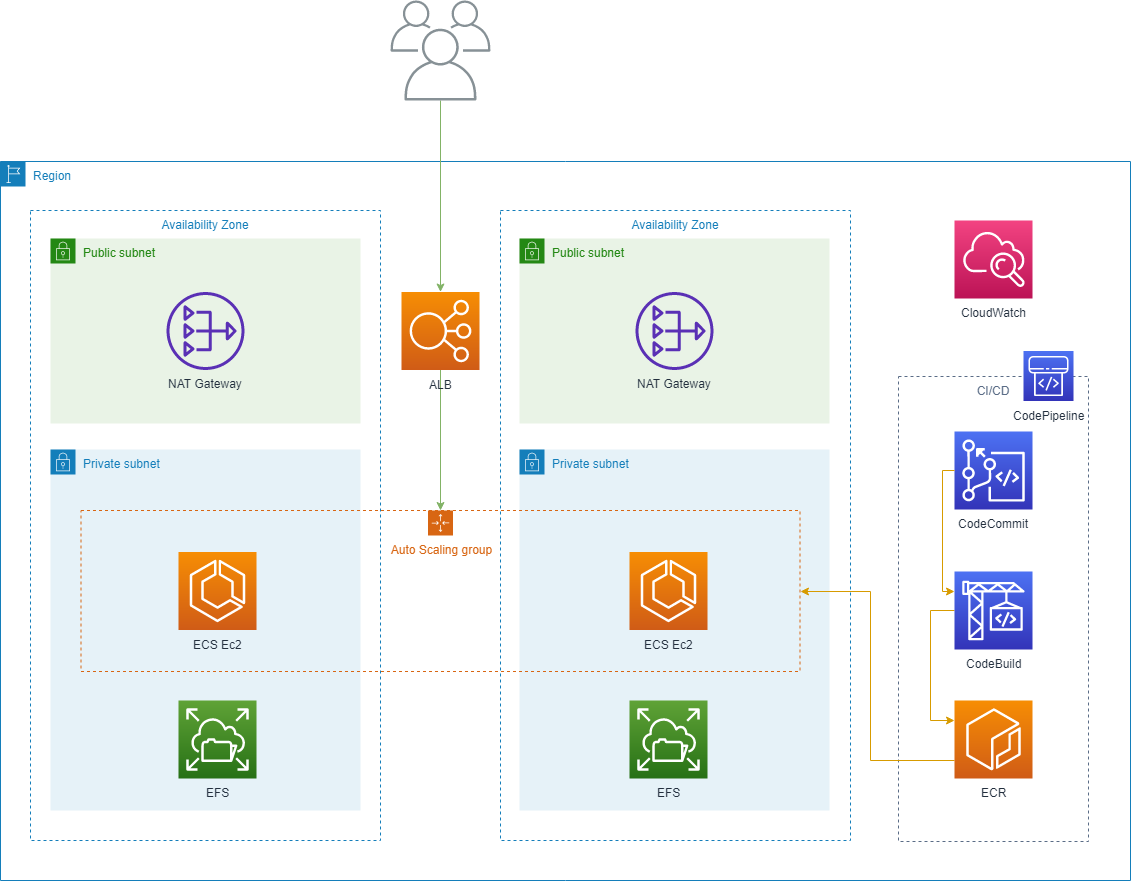
Commençons par votre application ! Partons du principe que vous utilisez des conteneurs, et que ceux-ci doivent permettre un stockage partagé distribué.
Cluster Docker
Commençons par le début : nous devons créer un cluster Docker, et nous devons bien exécuter vos conteneurs quelque part. Le service natif pour conteneurs AWS est ECS (Elastic Container Service) soit un service d’orchestration de conteneurs, qui nécessite une ou plusieurs machines virtuelles (EC2) pour fonctionner. C’est relativement facile si vous utilisez l’« Infrastructure as Code » – regardez le replay de ce webinaire pour plus de détails (webinaire en anglais) :
L’idée principale de l’« Infrastructure as Code » est que les systèmes et appareils utilisés pour exécuter un logiciel sont traités comme s’ils étaient eux-mêmes des logiciels.
Stockage distribué
J’ai évoqué le stockage distribué, c’est-à-dire un système NFS quelconque. Je vous présente le service géré AWS pour NFS appelé EFS (Elastic File Storage). Ses principaux avantages :
- Vous n’avez pas besoin de serveurs NFS gérés
- Vous n’avez pas à créditer un certain montant, il évolue en fonction de votre consommation, sans action de votre part
- Vous payez environ 0,08 $ (soit environ 0,07 €) par Go et par mois
J’ai rencontré énormément de difficultés avec le stockage distribué par le passé. Pour résumer, disons que j’ai passé quelques nuits blanches à cause de GlusterFS en version bêta. J’apprécie donc beaucoup EFS.
Aussi, l’utilisation d’un outil comme EFS est formidable lorsque vous n’avez pas le temps ou les ressources de changer votre application pour utiliser S3, ce que je vous recommande vivement de faire si vous le pouvez.
Équilibreur de charge
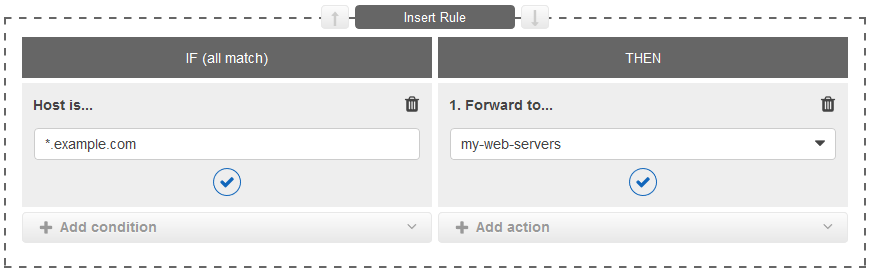
Après avoir ajouté le cluster, il faut répartir la charge. Cependant, si vous avez une architecture de services multiples ou de microservices, un équilibreur de charge classique ne suffit pas !
Pourquoi ? Parce que vous devez acheminer le trafic vers différents microservices basés sur le chemin ou l’hôte.
En règle générale, pour les problèmes d’hôte (host), on avait tendance à simplement ajouter un équilibreur de charge par service (ce qui revient vite cher pour les microservices). Mais pour le chemin (path), vous devez disposer d’un outil comme HAProxy, ce qui ne constitue pas la meilleure solution, car vous avez désormais autre chose à gérer.
AWS propose ALB (Application Load Balancer) qui nous donne un routage avancé (hôte, chemin et plus encore) sans avoir rien à gérer. Cette image issue de la documentation AWS vous montre à quel point il est simple de router vos microservices.
Dimensionnement automatique
Nous avons maintenant le cluster, le stockage et l’équilibreur de charge. Il faut ajouter le dimensionnement automatique pour gérer les pics de trafic et réduire les coûts de votre projet PHP, ce que nous pouvons faire à deux niveaux : le cluster et vos services.
Mais pourquoi avons-nous besoin de deux niveaux ? N’est-ce pas un peu complexe ?
Si vous ajoutiez un autre serveur à votre cluster Docker tout en conservant le même nombre de conteneurs (avec le CPU et les limites de mémoire), cela vous aiderait-il ? Pas vraiment.
Si vous souhaitez vous simplifier la vie et ne vous occuper que d’un niveau de dimensionnement automatique, je vous conseille d’utiliser des « conteneurs sans serveurs » (ECS Fargate) qui ne prennent pas en charge EFS.
Cela implique que vous fassiez passer le stockage à S3, et que vous ne puissiez pas toujours changer l’application.
Le choix des bonnes métriques de dimensionnement constitue un sujet complexe ; je vais donc me contenter de vous indiquer les métriques que vous pouvez utiliser.
Pour mettre le cluster à l’échelle, je vous conseille de regarder du côté des métriques EC2. Attention : pour utiliser les métriques de mémoire, vous devez installer l’agent CloudWatch.
Pour vos microservices, vous avez vos métriques de cluster et de service, toutes disponibles au même endroit : CloudWatch.
En réalité, il existe bel et bien une autre option. Comme nous utilisons un équilibreur de charge d’application (ALB), nous pouvons réaliser la mise à l’échelle en nous basant sur le nombre de requêtes que nous avons ou d’erreurs que nous voyons. Retrouvez la liste complète des métriques disponibles sur cette page de documentation.
Pipeline de release
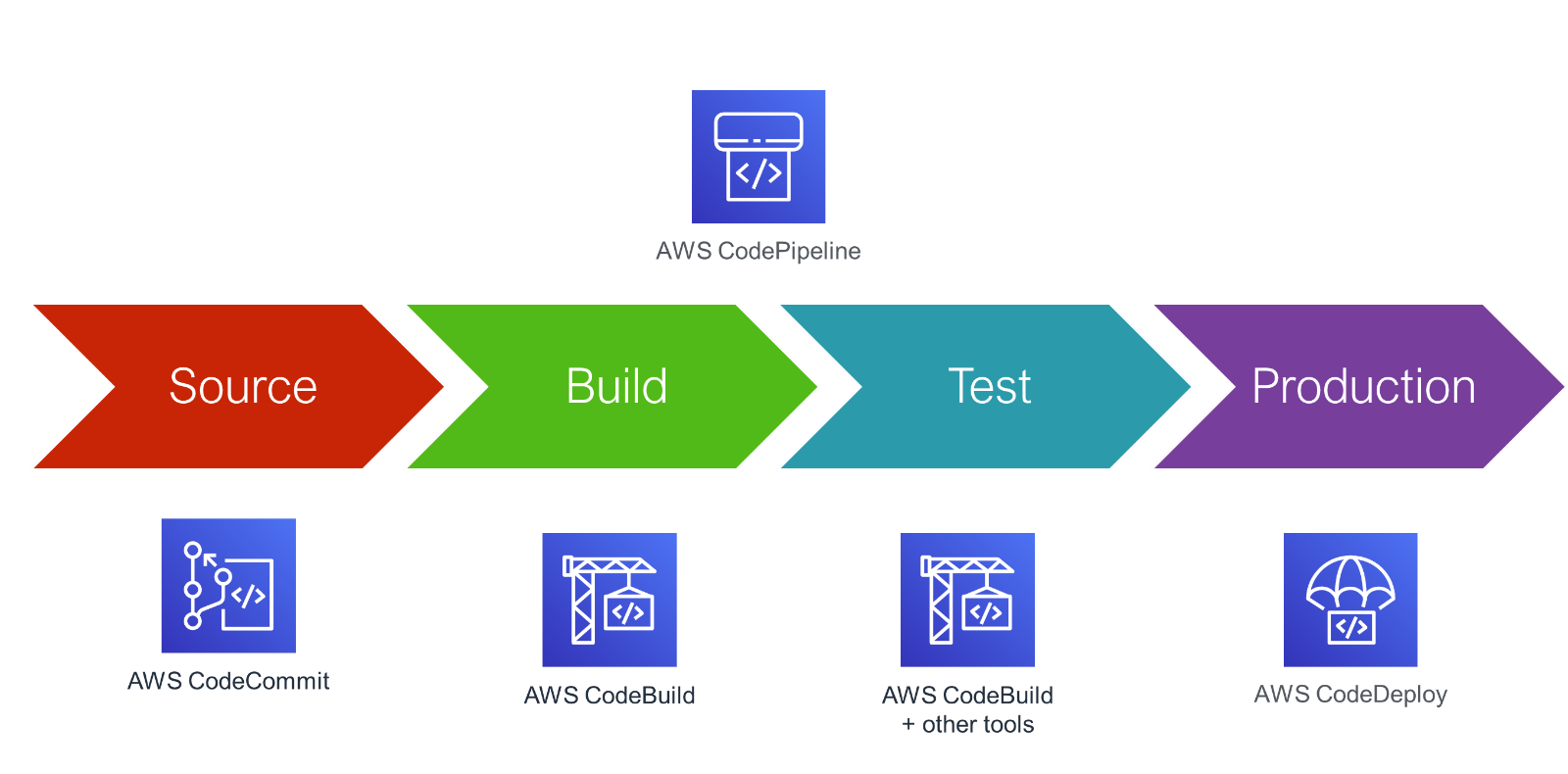
Pour implémenter un pipeline de CI/CD (pipeline d’intégration et de livraison continues) pratique, nous commençons par CodeCommit, qui est en fait un service Git hébergé. Vous y poussez votre code (code de l’application et Dockerfile), ce qui lance CodeBuild.
Codebuild crée le conteneur sans serveur de votre choix, qui prend une liste de commandes définie par vos soins (installation de composer, réduction des fichiers statiques, développement de conteneur), les exécute et pousse le conteneur sur ECR (Elastic Container Registry) – ECR étant votre registre de Docker hébergé et privé.
CodePipeline détecte qu’une nouvelle version de votre image existe et la déploie automatiquement dans votre cluster ECS.
Et voilà, vous avez désormais un pipeline entièrement automatisé pour déployer vos microservices. AWSome !
Pour conclure : en laissant AWS faire le gros du travail pour votre projet PHP, vous profitez d’un cluster Docker avec une charge équilibrée, à dimensionnement automatique et doté d’un pipeline de release automatisé pour vos microservices !
Dans le même domaine :








